%201.svg)



HIPAA Compliance Checklist for 2025

Most IT teams know how to budget for SaaS. AI is different.
A developer switches from Sonnet to Opus. Someone uploads an entire codebase into Claude. A workflow agent starts making 12 model calls instead of one. Nobody adds or buys more licenses. Yet the monthly bill keeps climbing.
That's tokenmaxxing, when users consume significantly more AI tokens than a task requires. Because AI usage naturally evolves toward larger context windows, more powerful models, and more complex agent workflows.
The result is a budgeting problem most organizations aren't prepared for. A team that costs $8,000 a month in Q1 can cost $35,000 a month in Q3 without any change in headcount.
CloudEagle.ai gives IT and Finance teams per-user token consumption data, model tier visibility, and run rate forecasting. So token overspend becomes something you see coming.
In this article, we'll break down what tokenmaxxing is, why it compounds faster than most teams expect, and what visibility actually looks like when you have it.
TL;DR
- Tokenmaxxing occurs when AI usage grows through larger models, longer prompts, and complex agent workflows rather than more users.
- Unlike SaaS seats, AI costs scale with token consumption, making spend difficult to predict and control.
- Common drivers include premium model overuse, context window inflation, repetitive prompts, and agent call chaining.
- Most organizations lack per-user visibility, model-level insights, and forecasting needed to prevent AI budget overruns.
- CloudEagle.ai helps teams monitor token consumption, govern model usage, and forecast AI spend before costs escalate
1. What is Tokenmaxxing? Why Suddenly It’s a Concern?
Tokenmaxxing is when employees consume far more AI tokens than they should, causing AI costs to grow faster than expected. It's becoming a concern because AI spending scales with usage, not just users.
One example of such a case is Uber. Recently. According to Fortune, Uber used its entire 2026 AI budget within just 4 months. That said, unlike traditional SaaS, AI costs increase as usage becomes more advanced.
- Premium Models Become The Default: Teams use Opus, GPT-4, or Gemini Ultra for tasks smaller models can handle.
- Context Windows Keep Growing: Users upload entire documents, codebases, and datasets instead of relevant sections.
- Agents Multiply Token Consumption: A single workflow can trigger multiple LLM calls behind the scenes.
- Usage Matures Over Time: Better prompts and deeper adoption naturally increase token volume.
This is why AI pricing often surprises organizations. The spend on tokenmaxxing doesn't grow because of more licenses. It grows because existing users consume more tokens every month.

2. Token-Based Pricing Doesn't Scale the Way SaaS Seats Do
With seat-based SaaS apps, the math is predictable:
- 100 seats at $X per month
- Headcount goes up, cost goes up proportionally
- Next quarter looks roughly the same unless you hire
Token-based AI pricing works differently:
- You pay for what your team consumes and consumption doesn't trend linearly
- It accelerates as users get more complex, prompts get longer, and agents start chaining calls
- A team that costs $8,000 a month in Q1 can cost $35,000 by Q3 without adding a single user
The tokenmaxxing budget surprise usually arrives at quarter-end. IT discovers that a handful of users account for most of the organization's AI spend. And the pricing model rewarded that with a bill nobody forecasted.
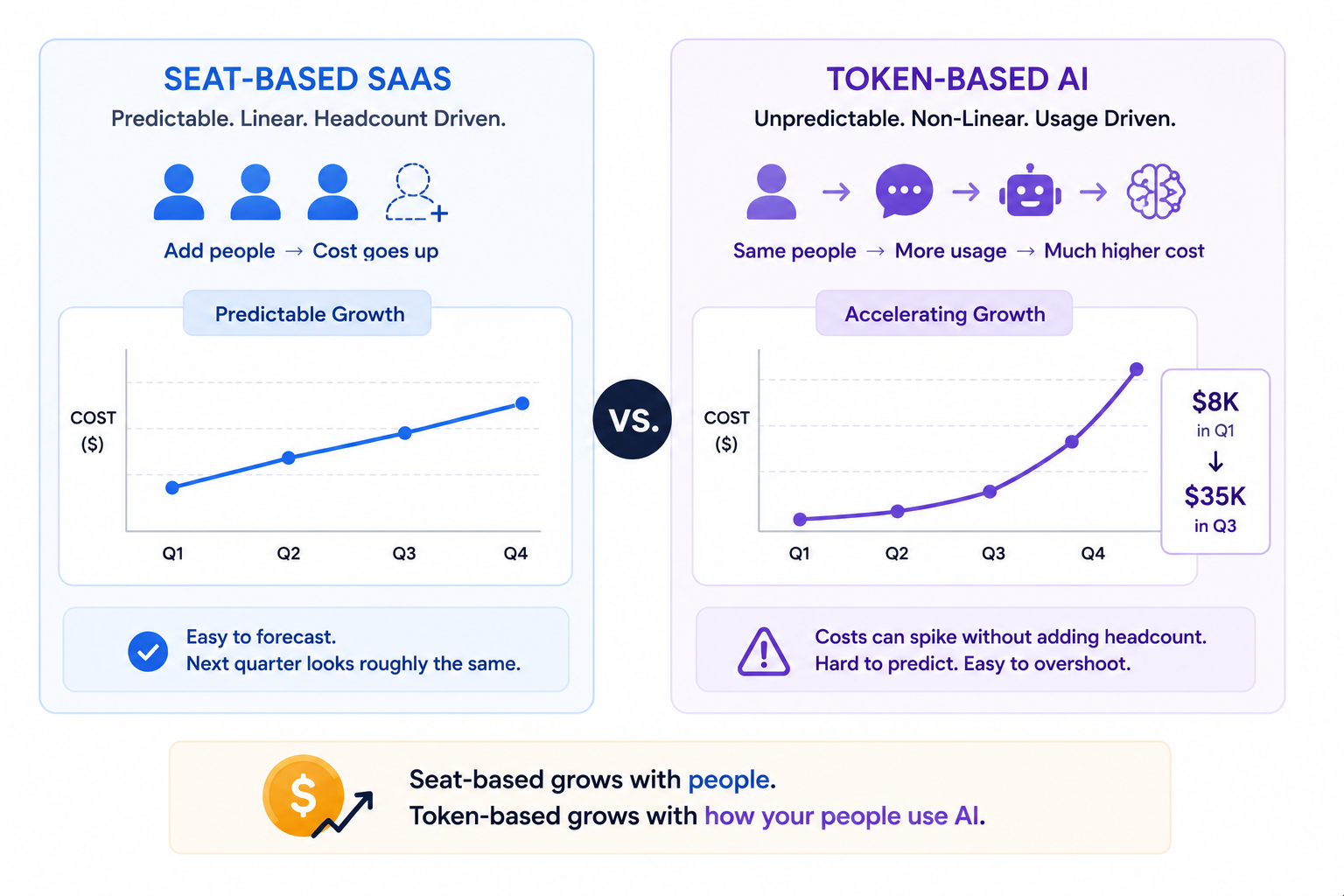
That's what makes token-based pricing structurally different. The cost doesn't grow when you add employees. It grows when existing employees get better at using AI.
3. What Tokenmaxxing Actually Looks Like in Practice
Tokenmaxxing rarely looks like reckless spending. In most cases, it looks like employees are trying to get better results from AI. That's why it's hard to spot.
The following examples are the four most common ways tokenmaxxing shows up inside enterprise AI environments.
A. Model Over-Selection
One of the fastest ways to tokenmaxxing is using the most powerful model. A simple summary doesn't always need Opus, GPT-4, or Gemini Ultra. Yet, many users default to them because they're available.
Honey Thakur (CloudEagle AE), described it,
"People are over-ageing on Claude, The token sizes increase and they are burning through cache really quickly."
The result is higher token consumption without a proportional increase in value.
B. Context Window Inflation
Context windows tend to grow over time. Instead of sharing a few relevant pages, users upload entire contracts, codebases, or data exports.
The problem is simple: every token in the context window costs money. Relevant tokens and irrelevant tokens are billed the same way.
C. Unoptimized Repetition
This is another excellent example of tokenmaxxing. Many teams rerun the same long-context prompts repeatedly without using caching or other optimization techniques.
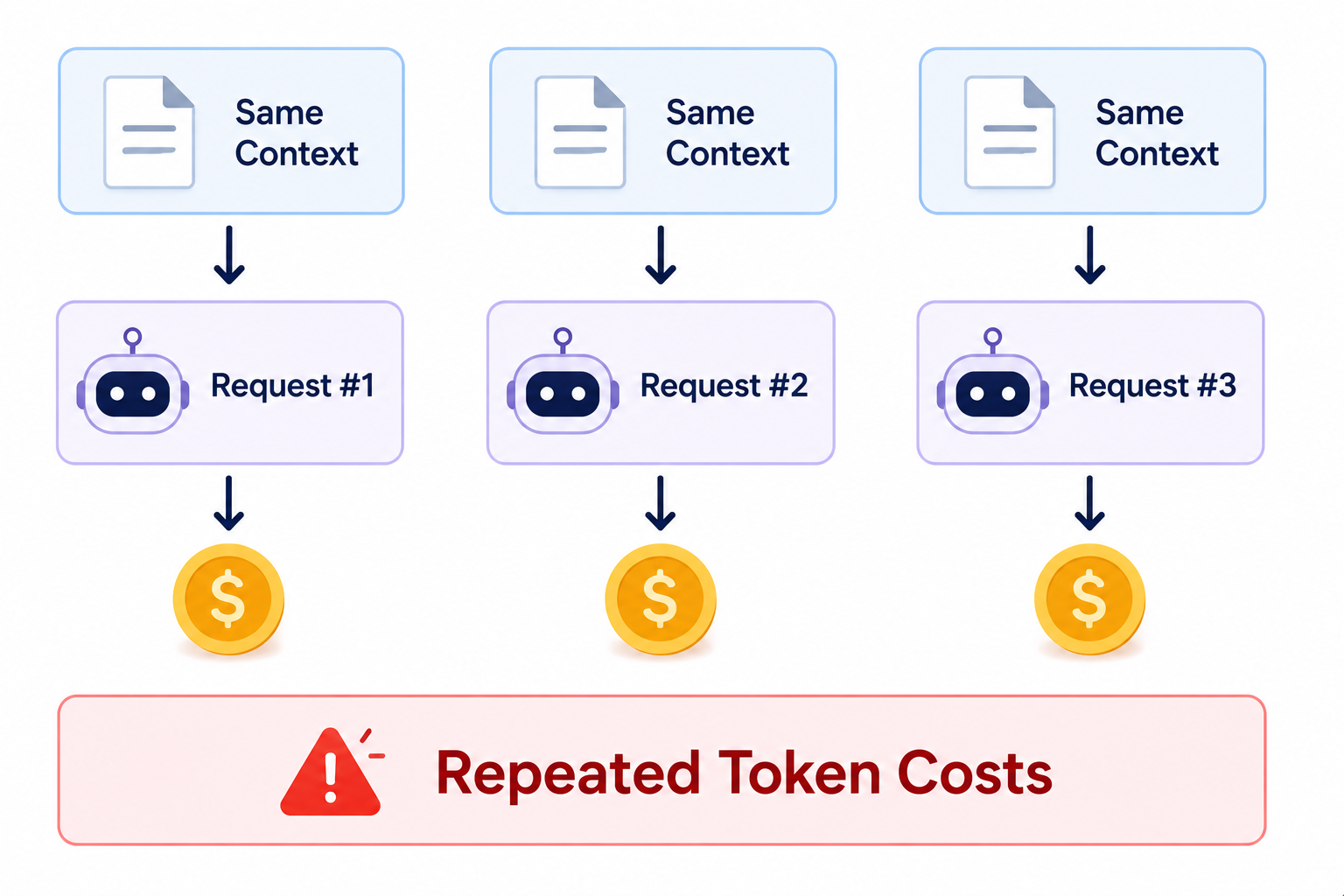
That means the model processes the same background information again and again, consuming the full token cost each time even when most of the context hasn't changed.
D. Agent Call Chaining
A single prompt may use one model call. An agent workflow can use ten or fifteen. The risk grows when employees start building personal agents at scale.
One security leader described seeing "a large number of personal agents and AI agents being created" and wanting to "almost claw that back" to regain governance. Every additional model call increases token consumption, and those costs multiply each time the agent runs.
4. Tokenmaxxing Visibility Gap: By the Time You See It, It's Already Happened
The biggest problem with tokenmaxxing isn't the consumption itself. It's that most organizations discover it after the spend has already occurred.
Claude Console, OpenAI's usage dashboard, or Microsoft Copilot Dashboard show aggregate consumption. They don't give you a per-user breakdown in a useful format.
- Usage data is aggregated, not actionable: Total consumption is visible but per-user breakdowns require someone to manually disaggregate before anything can be done with the data.
- Tracking requires manual work: One IT leader described exporting from Purview, running VLOOKUPs against the Copilot Dashboard, and rebuilding pivot tables every two weeks just to report usage. "That's old school. I don't have time for that."
- API consumption is hard to attribute: When API keys are distributed manually with user names embedded, there's no automated breakdown and no alert when a single user's usage spikes unexpectedly.
By the time finance sees an overage, the budget impact from tokenmaxxing has already happened. That’s why run-rate forecasting is important.
Week-over-week per-user trend data that lets you project where spend will be in 30, 60, or 90 days before the invoice arrives.
As one procurement analyst managing a six-tool AI stack put it: "We want to estimate run rates and forecast off of the adoption and spend trends with the vendors." That's the difference between managing AI spend and reacting to it.
5. Three Things You Need in Place Before the Next AI Renewal
If tokenmaxxing is already happening, the goal isn't to stop AI adoption. It's to understand where consumption is coming from and whether it's creating value.
A. Per-User, Per-Model Consumption Visibility
Before renewal, you should be able to answer:
- Which users consume the most AI tokens?
- Which models are driving the highest costs?
- How has usage changed week over week?
- Which teams are increasing consumption fastest?
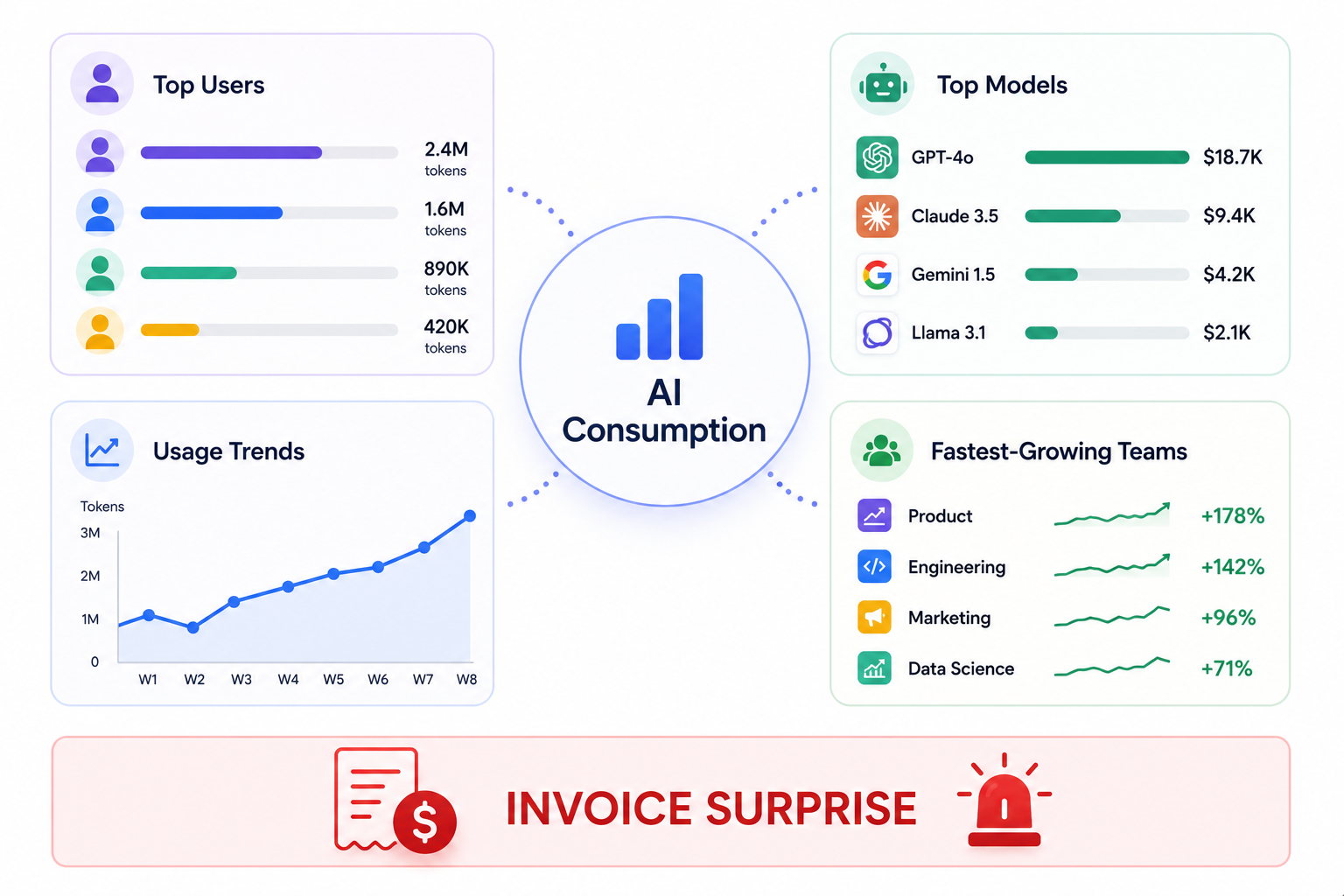
Without this visibility, tokenmaxxing becomes a finance problem only after the invoice arrives.
B. Model Tier Governance
The goal isn't to restrict AI usage. It's to ensure the right model is used for the right task.
- Identify users defaulting to premium models for routine work
- Compare usage across Opus, Sonnet, GPT-4, and other tiers
- Understand where premium models deliver measurable value
- Optimize model selection before costs compound
As our team consistently observes across enterprise deployments, "people are over-ageing on Claude" because larger models often become the default choice regardless of task complexity.
C. Agent Inventory and Call Chain Tracking
Agents are becoming one of the biggest drivers of token consumption.
- Maintain an inventory of active AI agents
- Track who created each agent and whether they still own it
- Monitor how frequently agents run
- Measure how many LLM calls each workflow generates
A single AI agent may trigger 10 to 15 model calls for one task. So where employees are building personal agents rapidly, token usage can grow far faster, far faster than anyone budgeted for.
6. How CloudEagle.ai Help Enterprises Track and Manage Token Consumption?
CloudEagle.ai continuously pulls usage and cost data directly from Claude, Cursor, Gemini, and other AI vendors.
The platform maps every token consumed and every credit spent against contract terms, and presents consolidated spend data across all AI and SaaS tools in a single dashboard.
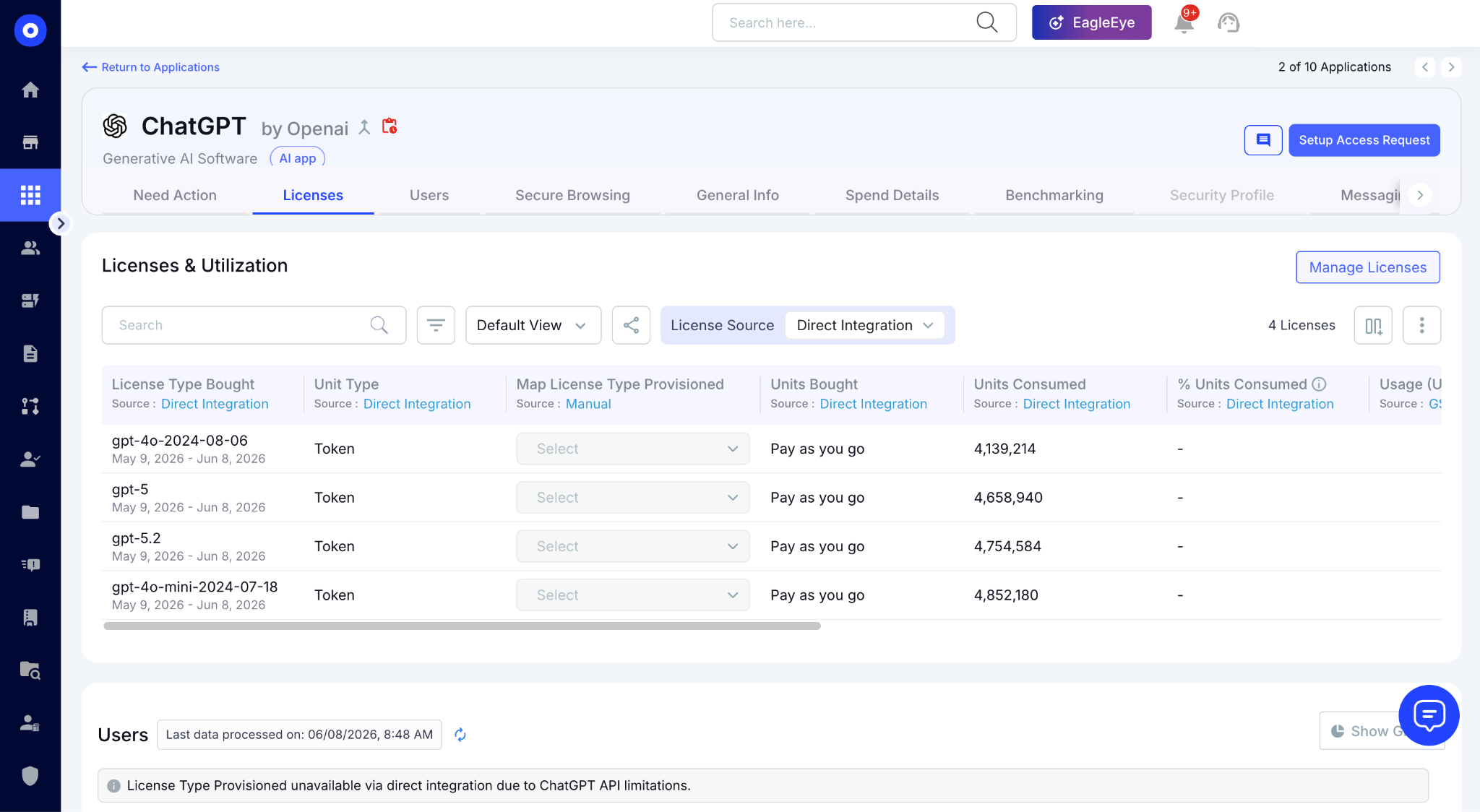
Here's how CloudEagle.ai prevents tokenmaxxing for each team:
- Finance: Reconcile consumption-based invoices against actual budgets. Every credit spent is mapped to the team or cost center that generated it
- Procurement: Walk into renewals knowing exactly what was used, which models drove the most cost, and where consolidation creates leverage.
- IT and Engineering leads: See per-user, per-model consumption trends week over week. Identify who is using premium models for routine tasks.
- Leadership: Answer the standardization question of Claude, Copilot, or Gemini with actual usage data instead of vendor pitches.
Set spend thresholds by tool, team, or total AI budget. When Cursor usage in your engineering org climbs 60% in 30 days, you know before the invoice lands.
That's the difference between run-rate forecasting and end-of-quarter surprises. When you can see spending, you can control it. When you can control it, you can scale it.
AI Costs Move Faster Than Budgets


7. Conclusion
Most organizations don't realize they have a token problem until they have a budget problem.
That's because tokenmaxxing isn't caused by misuse. It's caused by normal AI adoption. Users choose better models, upload more context, and build more agents as they become comfortable with AI.
CloudEagle.ai gives IT, Finance, and Procurement teams exactly that: per-user token consumption data, model tier visibility, and run-rate forecasting across all AI tools in the stack.
Because when you can see tokenmaxxing early, you can manage it before it becomes next quarter's budget surprise.
8. FAQs
1. How much text is 1,000 tokens?
1,000 tokens equals roughly 750 words or 4,000 characters in English. A standard email is around 200 to 300 tokens; a one-page document around 400 to 500.
2. What is tokenization in ChatGPT?
Tokenization is how ChatGPT breaks input text into smaller units called tokens before processing. A token can be a word, partial word, or punctuation mark and every token in your prompt and response contributes to your bill.
3. How much do 1,000,000 tokens cost?
Cost varies by model: input tokens range from $0.25 to $15 per million, output tokens from $1.25 to $60. Premium models like Claude Opus and GPT-4 sit at the higher end; lighter models like Haiku significantly lower.
Your Tokens Are Telling A Story



.avif)




.avif)
.avif)




.png)